

The world has become more global and complex, where everything is controlled by software from airplanes to cars, every day we depend more and more on software that is unreliable and expensive to maintain, if we do nothing, we will continue to have serious accidents such as Boeing 737Max.
Our lives are being affected by the quality of the software. Knowing that the 40% of errors of software are design errors, we need a software architecture that guides the development of quality software, together with the problem of scalability and availability that exists in the software industry.
Since the birth of the computer in 1938, as of today, 2019, there has been a tremendous advance in the processing capacity (number of operations per second) that a computer can perform, we go from less than 1 to 187,000,000,000,000,000 (187 billion). Even a home computer processes 135,000 million. It has not been the same in the software development industry, many programs are coded today in the same way as 30 years ago. Hardware development is faster than software, and this slows the progress of humanity.
The problem of scalability is not only when we connect several computers, the manufacturers of processors faced with the difficulty of manufacturing faster processors, to increase the power they are adding more processors in parallel, these are called cores, even the phones have multi-core processors , and in 2019 a CPU with 400,000 cores.
If we had a time machine and brought a software developer and a hardware developer 30 years ago, the software developer would update in a couple of hours and could start working, instead a hardware developer would have to spend months studying the new techniques to be updated. Why does that happen? one of the reasons is that poorly designed hardware would mean a great loss to the manufacturer company and for that reason, the brightest minds participate in the design of hardware, however a badly designed software can be changed from one moment to another, even making a fairly good and faulty software is a great business, since it allows to sell the same software several times with the excuse that the new version solves the failures of the previous version.
Software architecture evolution
At first the software worked on a computer where everything was under developer control. Given the problem of allowing the software to work on various types of computers, operating systems were developed, this also allowed several software to run on the same computer. Each stage adds a new level of programming facilities as well as greater complexity and source of failures.
Then came the client-server architecture, where part of the computations are performed by the server computer and another part on the client computer, this adds another degree of complexity, since although both are under programmer control the connection between these two computers by A data network implies a new source of failures (uncertainty).
Analyzing this summary and partial evolution of the software development architecture we can predict that the new software architecture will bring new facilities and another layer of complexity.
In summary, the problems we have are:
- Gigantic, slow monolithic software, which increasingly costs more money to maintain or improve.
- Low probability of concurrence and availability.
- Users with privileges which do not allow a reliable audit.
- The network is unreliable and insecure, it is not homogeneous and its topology changes, its delay “Latency” is not zero, its side width is finite and the transport cost is not zero.
Organic Architecture
Perhaps there are many solutions and a single architecture does not serve everything, for us, the solution to the problem of quality, scalability and complexity is Organic Architecture.
We have combined different advances in architecture, design patterns and software methodologies that in our opinion are complementary, and we call this architecture “organic” since we see some similarity with the way biological cells work, even in the way in which collective decisions are made.
The key point of our architecture is not that it works or is efficient, it is that it is “maintainable” by the developers, that is maximize functionality and flexibility while minimizing the effort. This is achieved with clear, well-defined and separate abstractions, since we do not start with the assumption that everything is under the control of the developer, but quite the opposite, there will be changes in software requirements, failures and uncertainties and it is the duty of the software developer to prepare for these scenarios, and all this should be as transparent as possible to the end user, as dramatic as possible, trying to make them imperceptible by the end user.
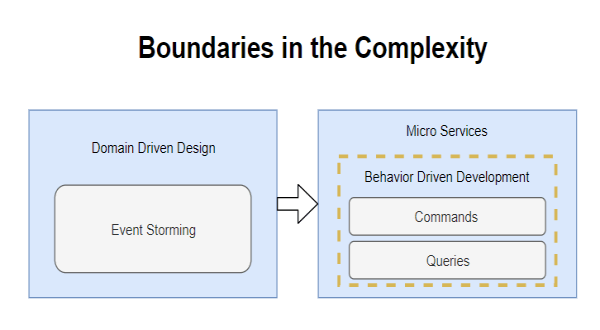
To tackle the problem of complexity begins the “Domain Driven Design” methodology of EricEvans, which allows us to establish the domain and “Boundaries” limits of all the “Micro Services” of the system. We also help each other with the complementary “Event Storming” methodology and finally obtain the “Micro Services” that we are going to implement.
The next step is to implement these “Micro Services” and for this we use the methodology “Behavior Driven Development” where the first thing to develop are the tests that will allow us to check the proper functioning of our “Micro Service”, Here also the separation begins of the “Commands” commands of the “Queries” queries in our “Micro Service”, we can also see it as the separation of the writing side of the reading side, as well as the separation of the functionality of the data.
The functionality is separated from the data, because both are contradictory and complementary, to understand it better we recommend reading Robert C. Martin (Uncle Bob) in his article on ” Classes vs. Data Structures “ remember that we look for the” maintainability “of the code and these separations are the key to achieve it, it is also the same reason why which functional programming has become fashionable.
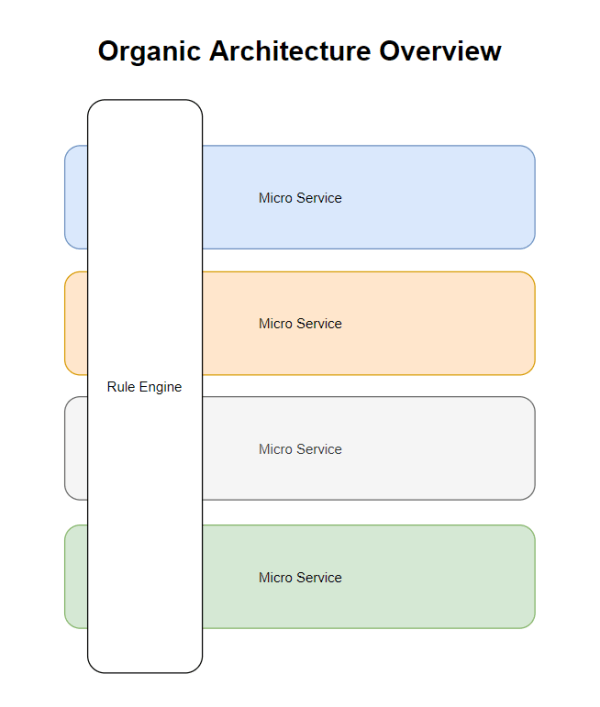
By obtaining our “Micro Services” we add another Additional Service to the “Rule Engine” which is a cross-sectional service to all of our Micro Services, the “Rule Engine” allows us to compose cross-functional functionality to all of our Micro Services, thus obtaining the ability to adapt to additional requirements of the users of our complex system without having to re-analyze and develop the entire system. The “Rule Engine” is an old idea, our innovation consists in this relationship that we give with the “Micro Services” and although it seems that it is against the DDD methodology that seeks the decoupling between “Micro Services” what it does is complement them without coupling them.
With the “Rule Engine” adding new transversal functionality (which affects several Micro Services) becomes easier, it is adding functionality to the “Rule Engine” and adding the interface and functionality required in the Micro Services Involved.
The “Rule Engine” is not a supervisor of the Micro Services, it is more like a Meta Service that composes its own information and other services.
Micro Service
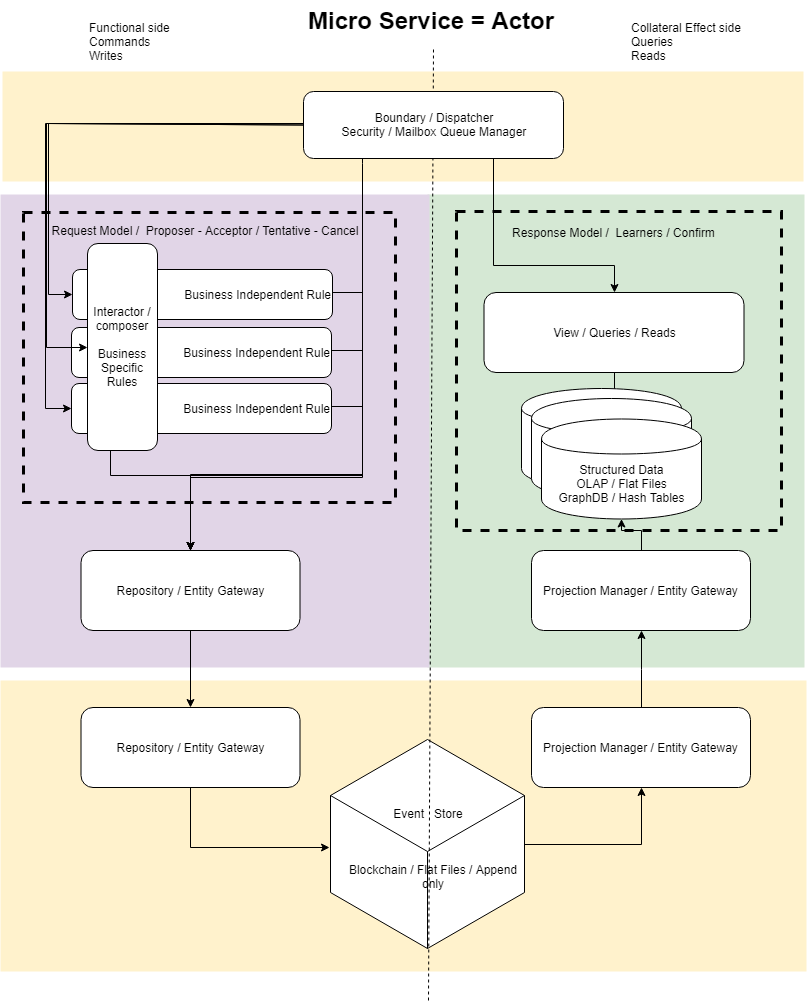
Now if we get to the heart of our architecture to solve the problem of scalability.
We combine the CQRS + Event Sourcing + Actor Model Programming + BlockChain pattern.
Helland in his article “Life Beyond Distributed Transactions” with his great experience introduces us to the solution to the problem of The scalability and our architecture continues this work.
CQRS “Command Query Responsibility Segregation” + “Event Store” is the work of Greg Young where the separation of the reading of the writing is add “Event Sourcing” to have the flexibility of various projections of the same data, this data is now stored raw in a “log”, “Event Store” to which you can only add data (this data is made), No updates of any kind.
One of the facilities offered by the “Event Store” is to further improve this separation of functionality and data, since it allows to have multiple optimal representations of the same data (Projections) that is in the Event Store.
The “Event Store” is now the source of the truth, but it is not externally accessible, which leads us to the problem of eventual consistency, that is, the data obtained from the queries that are made on the side of the reading will eventually be updated, since they are a projection of the data, but not the source of the truth.
On the side of the commands, the business logic is separated into independent business rules, from the specific business rules, which are transversely executed by an Interactor / Composer that applies them specifically. This abstraction has the same purpose as the “Rule Engine” in relation to the “Micro Services” in the previous diagram.
Vaughn Vernon , is another expert who has inspired us, since it also concludes the need to apply “Actor Model” a design of 1973, and in the words of Alan Kay “Actor model retains more than I thought are the important ideas in object programming” Thus, Actor Model is object programming done in the right way.
“Actor Model” is added to give us its concurrency and supervision functionality. The “Mailbox” of “Actor Model” is our “Boundary / Dispatcher / Security / Mailbox” that receives the messages and saves them in the “Event Store”, and the “Event Store” allows us to make the life cycle of the “Actor “, that is to say, creation and destruction of” Actors “in a transparent way, since the new” Actor “can continue the execution as far as the project of the Event Store is presented.
Until now the problem of “Actor Model” has been the creation and dynamic destruction of “Actors” and secondly the tests and debug, this is solved with an “Event Store” that when implemented as a BlockChain distributed among a variable quantity of dynamic actors, leaving only the problem of eventual consistency. This idea of connecting “Actor Model” with a distributed log (blockchain) is another innovation of ours.
It remains to develop in this architecture the “Workflow” of messages, both those of “Actor Model”, as the messages between “Micro Services”, this Workflow is contemplated in the architecture, but is not detailed, there are works on Transactional “Workflow” (Tentative – Cancel – Confirm). For us this is detailed engineering, which we will develop when we realize this architecture that we have designed.
Note: The problem of synchronizing a distributed log, both the industry and the academic world consider it solved with the Paxos and RAFT algorithms and for the Byzantine consensuses (with failures due to malicious participants) PBFT, HoneybadgerBFT , BEAT or HotStuff.

Benefits of Organic Architecture
- Maximum functionality and flexibility while minimizing effort, which leads to cost reduction.
- Transparency in updates and failures – service restart, which increases availability.
- Reduction of the coupling between micro services.
- Allows Software Monitoring.
- Focused on the mental model of Events and Activities.
- Reconstruction and time travel, allowing Audit and Debuging.
- Good separation between business logic, data structures and components.
- Optimization of data structures (projections).
- Break the bottleneck between readings and writings.
- Raise the possibility of concurrence.
- Independence among the various development teams (each with its “Micro Service”).
- Simplify and harden the messages.
This architecture requires the support of a Framework / Library, which takes the weight of the code that knows the details of the scale management, leaving the business logic with its projections to the developer. The workflow of the messages for the management of eventual consistency and other asynchronous messages between “Micro Services”, can be implemented using the nng library and the encryption of the communication with the wireguard library.





